About Document Conversion Service
The Document Conversion Service provides a REST API to convert binary data from one format to another. For example, a JPEG image could be converted to a PDF file. Another use case is text extraction from different document types. The actual content conversion is not implemented by the Conversion Service. The service offers an interface for plugins that perform the actual conversion.
Configuration
There might exist several plugins that may fulfill a given request, so you can configure which plugin to use for a given request. By default, the service just selects the first available plugin that claims to support the requested source and target mimetypes.
In order to configure this, specify a list of use cases in your application.yaml in the key
rendering (for render plugins) or in the key extraction (for fulltext plugins).
Use cases for render plugins
Each use case consists of
-
sourceType-
a regular expression matching the mimetype to be converted
-
-
sourceClassifier-
an optional string to further qualify the type of source data supported by the plugin
-
-
targetType-
a regular expression matching the mimetype to be converted to
-
-
plugin-
the name of the plugin to use (by default the fully qualified class name, but can be specified by each plugin)
-
The optional sourceClassifier can be used to limit the type of input data supported by the plugin. For example, a
plugin might support application/xml data but only when the XML file is using a specific doc-type. The plugin-package
must contain a classification plugin that is able to classify input data accordingly.
For a given request the service will search the list in the given order and use the first plugin whose configured sourceType and targetType match the requests.
rendering:
useCases:
- sourceType: application/pdf
targetType: image/jpe?g
plugin: my-pdf-to-image-plugin
- sourceType: .*
targetType: .*
plugin: my-fallback-pluginThe configuration above will instruct the service to use the plugin with the name my-pdf-to-image-plugin for requests
to render PDFs to JPG or JPEG files. In any other case it uses the plugin my-fallback-plugin. Note that if
my-fallback-plugin would be listed before the other one every request would be handled by my-fallback-plugin.
Use cases for extraction plugins
Each use case consists of
-
sourceType-
a regular expression matching the mimetype to be converted
-
-
plugin-
the name of the plugin to use (by default the fully qualified class name, but can be specified by each plugin)
-
For a given request the service will search the list in the given order and use the first plugin whose configured sourceType matches the requests.
extraction:
useCases:
- sourceType: application/pdf
plugin: de.eitco.commons.conversion.plugins.oss.TikaFulltextOcrExtractionPluginThe configuration above will instruct the service to use the plugin with the name my-extraction-plugin for requests
to extract text from pdf files.
General configuration settings
Limiting the size of uploaded data
To limit the size of the uploaded data to be rendered, the following configuration properties can be used:
server:
undertow:
max-http-post-size: 30MB
spring:
servlet:
multipart:
max-file-size: 30MB
max-request-size: 30MBPlugins Overview
The service provides two plugin interfaces: RenderPlugin and FulltextPlugin. A RenderPlugin converts from one
document type to another. It defines a list of supported source mimetypes and a list of supported target mimetypes.
A FulltextPlugin can extract text from a document. It defines a list of supported source mimetypes. The target mimetype
is always text/plain.
Open source plugins
The document-conversion-plugins-oss library provides several
plugins based on open source libraries. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
A ZIP containing the library and additional dependencies can be downloaded from nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-oss</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-oss
de.eitco.commons.conversion.plugins.oss.PdfMergingContainerPlugin
Merges pdf files.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.OpenHtmlRenderPlugin
Renders from XHTML to PDF by using com.openhtmltopdf.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.TiffToPdfRenderPlugin
Renders TIF to Pdf using IText.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.PdfToImagesRenderPlugin
Renders from pdf to JPG,PNG.GIF,TIF by using apache pdfbox.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.PdfToMultiPageTiffRenderPlugin
Renders from pdf to TIFF Pages by using apache pdfbox.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.TikaFulltextOcrExtractionPlugin
Extracts text by using Apache Tika and Tesseract OCR.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.MsgAttachmentsExtractionPlugin
Extracts attachments from Outlook Message files and renders them to a single PDF.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.TikaFulltextExtractionPlugin
Extracts text by using Apache Tika.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.OpenPdfRenderPlugin
Renders txt to pdf with openpdf.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.oss.ImagesToPdfRenderPlugin
Renders from JPG,PNG,GIF to PDF by using apache pdfbox.
| Source media types | Target media types |
|---|---|
|
|
| The OpenHtmlRenderPlugin has a problem with xml-structures who doesn’t close the tags. This will give you an exception. |
Fulltext plugins
The following fulltext extraction plugins exist:
-
de.eitco.commons.conversion.plugins.oss.TikaFulltextExtractionPlugin-
extracts text from pdf, doc(x), xls(x), epub, html, msg, odp, ods, odt, pptx, rtf and xml files using open source java solutions (namely apache tika)
-
-
de.eitco.commons.conversion.plugins.oss.TikaFulltextOcrExtractionPlugin-
extracts text with ocr from pdf, doc(x), xls(x), epub, html, msg, odp, ods, odt, pptx, rtf and xml files using open source java solutions (namely apache tika and tesseract for ocr)
-
Enable tesseract ocr:
If you want to use the TikaFulltextOcrExtractionPlugin to extract text from images, you need to install tesseract.
In the following steps the installation will be explained.
-
Download and install tesseract from this page https://github.com/tesseract-ocr/tessdoc/blob/main/Downloads.md.
-
For Ubuntu for example: sudo apt install tesseract-ocr
-
-
Add tesseract to the path enviroment variables. For example in Windows you must add the following lines in the path:
-
{path to tesseract}\Tesseract-OCR
-
{path to tesseract}\Tesseract-OCR\tessdata
-
-
Add new language packages to tesseract tessdata directory. Download the packages from the following site https://ocrmypdf.readthedocs.io/en/latest/languages.html
-
The default language is english (tesseract shortname = eng)
-
If you add a new language you must add they also in the yaml
-
Also you can change the dpi for tessearct image extraction
-
extraction:
tikaOcrLanguage: "eng+deu"
tikaOcrDpi: 300Levigo Jadice plugins
The document-conversion-plugins-jadice library provides several
plugins based on Levigo Jadice libraries. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
A ZIP containing the library and additional dependencies can be downloaded from Nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-jadice</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-jadice
de.eitco.commons.conversion.plugins.jadice.JadiceToPdfPlugin
Renders various formats to PDF using Jadice.
| Source media types | Target media types |
|---|---|
|
|
Please note that Microsoft Office documents (Powerpoint and Word) are here not confronted with any formatting related issues.
Configuration considerations of Levigo Jadice usage
A RenditionUseCase describes the source- and target-mimetype of a conversion supported by a specific plugin. The configuration file below shows how the source-mimetype 'application/msword' to the target-mimetype 'application/pdf' is configured using the JadiceToPdfPlugin.
rendering:
useCases:
- plugin: de.eitco.commons.conversion.plugins.jadice.JadiceToPdfPlugin
sourceType: "application/msword"
targetType: "application/pdf"
containerUseCases:
- targetType: "application/pdf"
- plugin: de.eitco.commons.conversion.plugins.jadice.JadiceToPdfPluginMicrosoft Graph plugins
The document-conversion-plugins-msgraph library provides several
plugins based on Microsoft graph libraries. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
| If you want to use this plugin you need a Microsoft 365 account which can use sharepoint and azure. |
A ZIP containing the library and additional dependencies can be downloaded from nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-ms-graph</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-ms-graph
de.eitco.commons.conversion.plugins.msgraph.GraphRenderPlugin
Renders Microsoft Office Documents and some other formats to PDF using the Microsoft Graph API
| Source media types | Target media types |
|---|---|
|
|
Setup microsoft graph render plugins
If you want to use the graph render plugins you will need a technical user and a sharepoint drive. A technical user in azure is named "app registration". In the following we will explain how to get an azure app registration and the sharepoint drive id.
App Registration
Login into https://portal.azure.com/. And search for the App Registration now you will see the following windows and you can create a new app registration:
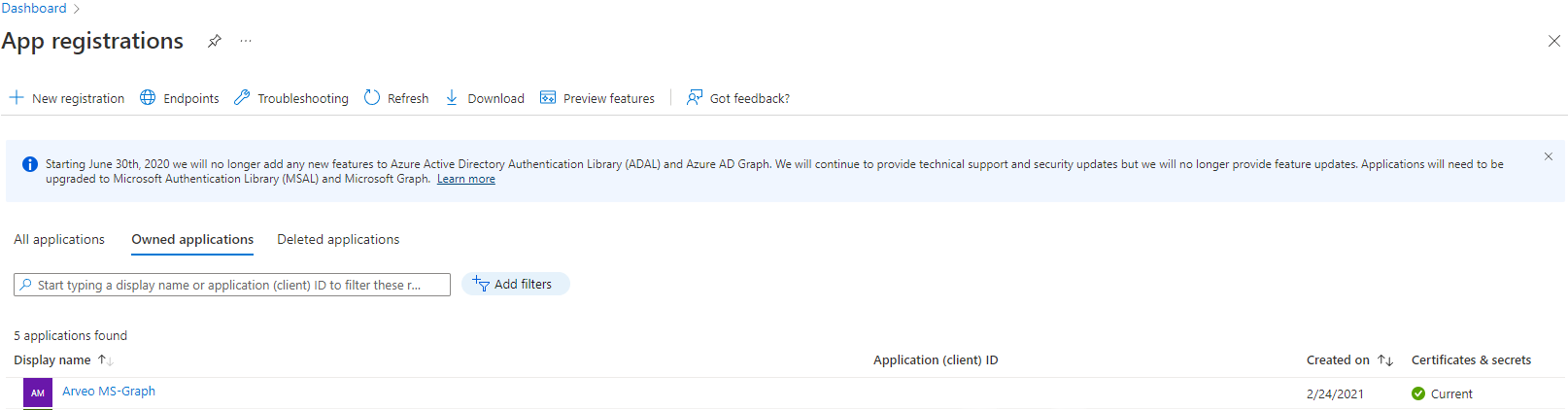
If you go into your new app registration you will find in the overview the client-id and the tenant-id.
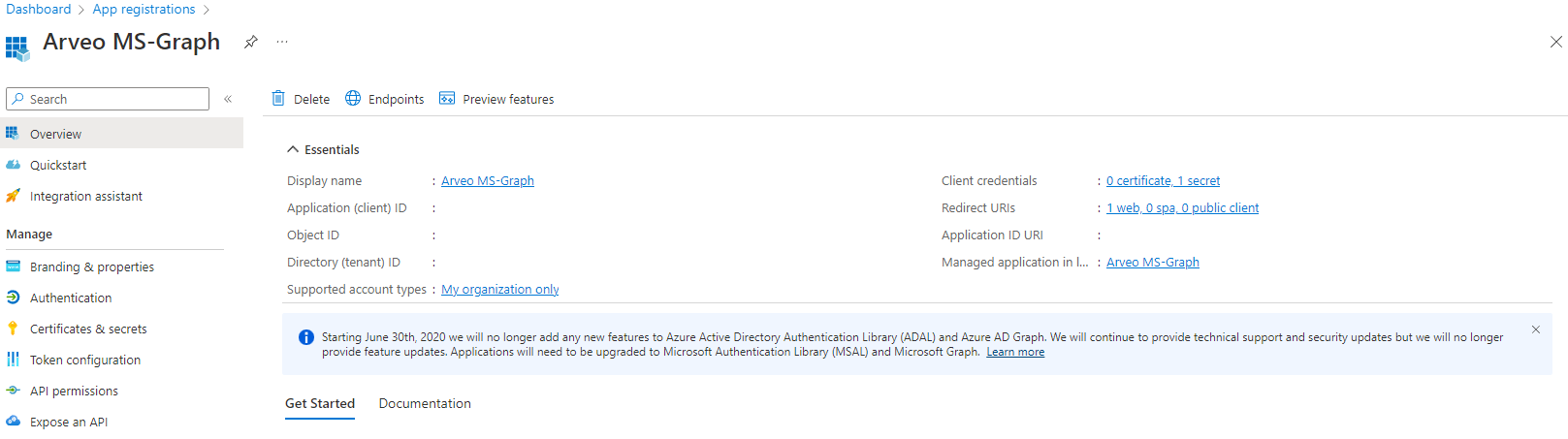
Now you can go to the api-authorization. The minimum you will need for the microsoft graph render plugin is the authorization named "Files.ReadWrite.All".
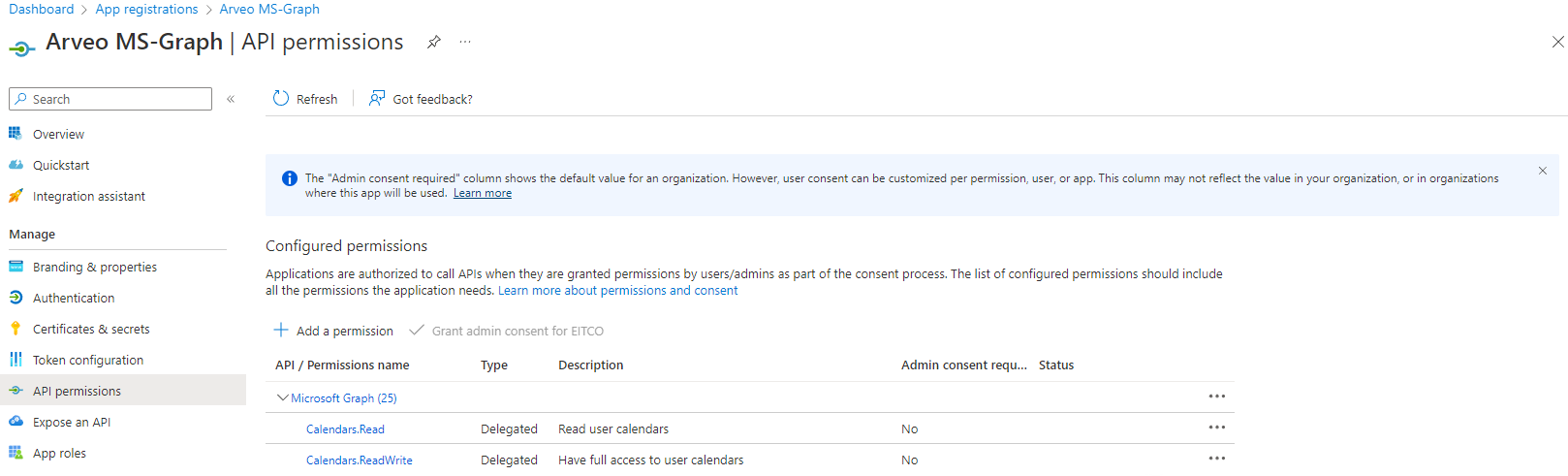
Now you can also set the authentication security for the app-registration. You can allow the app-registration to work in every tenant in azure or only in the tenant of yourself.
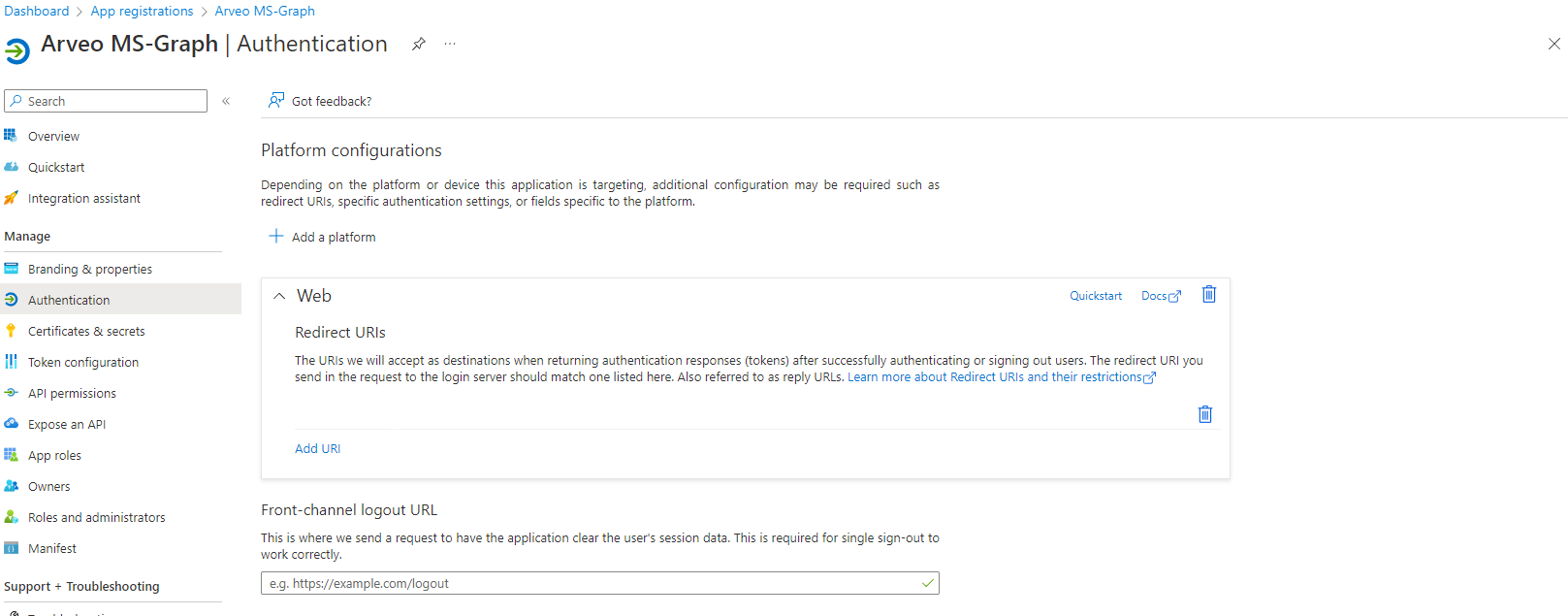
The last we will need is a secret this can generate in the following window.
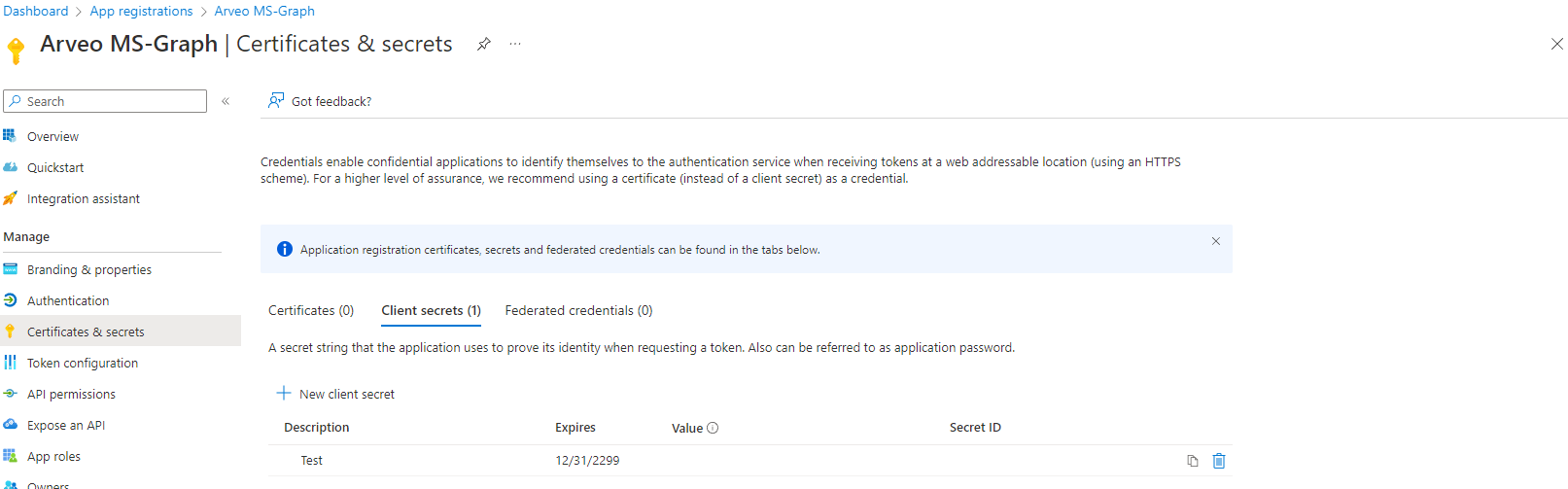
SharePoint
At first you need to create a sharepoint site and a drive. If you have create this you will need the SharePoint drive id. In the following we will explain how to get the drive id.
First you will need a SharePoint Teamwebsite. After you create the website, you can create a new document library [Optional].
A helper for the following request is the following Graph Explorer.
If you use this tool you musst be login with a user and you will set the permissions in "Modify permissions".
Get sharepoint site id
GET https://graph.microsoft.com/v1.0/sites/root:/sites/{site_url_name}
Example https://graph.microsoft.com/v1.0/sites/root:/sites/xxxxxxx
Response:
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites/$entity",
"id": "xxxxxxxx.sharepoint.com,0bbbfad6-xxxx-xxxx-xxxx-xxxxxxxxxxxx,3c5f2d82-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"name": "xxxxxxxx",
"displayName": "arveo"
}Get sharepoint drive id
GET https://graph.microsoft.com/v1.0/sites/{site_id}/drives
Example https://graph.microsoft.com/v1.0/sites/xxxxxxxx.sharepoint.com,0bbbfad6-xxxx-xxxx-xxxx-xxxxxxxxxxxx,3c5f2d82-xxxx-xxxx-xxxx-xxxxxxxxxxxx/drives
Response:
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#drives",
"value": [
{
"id": "b!XXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"name": "Conversion"
}
]
}YAML configuration
In the yaml of the document conversion service you must set the following to use the graph render plugin:
ms-graph:
azure:
credentialType: CLIENT_SECRET
clientId: <azure-client-id>
clientSecret: <azure-client-secret>
tenantGuid: <azure-tenant-guid>
sharepoint:
driveId: <drive-id>Alternatively, you can use username and password credentials to login to your azure account:
ms-graph:
azure:
credentialType: USERNAME_PASSWORD
clientId: <azure-client-id>
username: <username>
password: <password>
sharepoint:
driveId: <drive-id>Microsoft Azure Plugins
The document-conversion-plugins-ms-azure library provides several
plugins based on microsoft azure libraries. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
A ZIP containing the library and additional dependencies can be downloaded from nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-ms-azure</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-ms-azure
de.eitco.commons.conversion.plugins.msazure.AzureCognitiveOcrExtractionPlugin
Extracts text from images and pdfs by using azure cognitive services.
| Source media types | Target media types |
|---|---|
|
|
Setup Microsoft Azure fulltext plugin
If you want to use the azure fulltext plugins you will need a cognitive service in your azure portal.
Setup cognitive service
Login into https://portal.azure.com/. And search for the Cognitive Services (Computer Vision) now you will see the following window and you can create a new computer vision service:
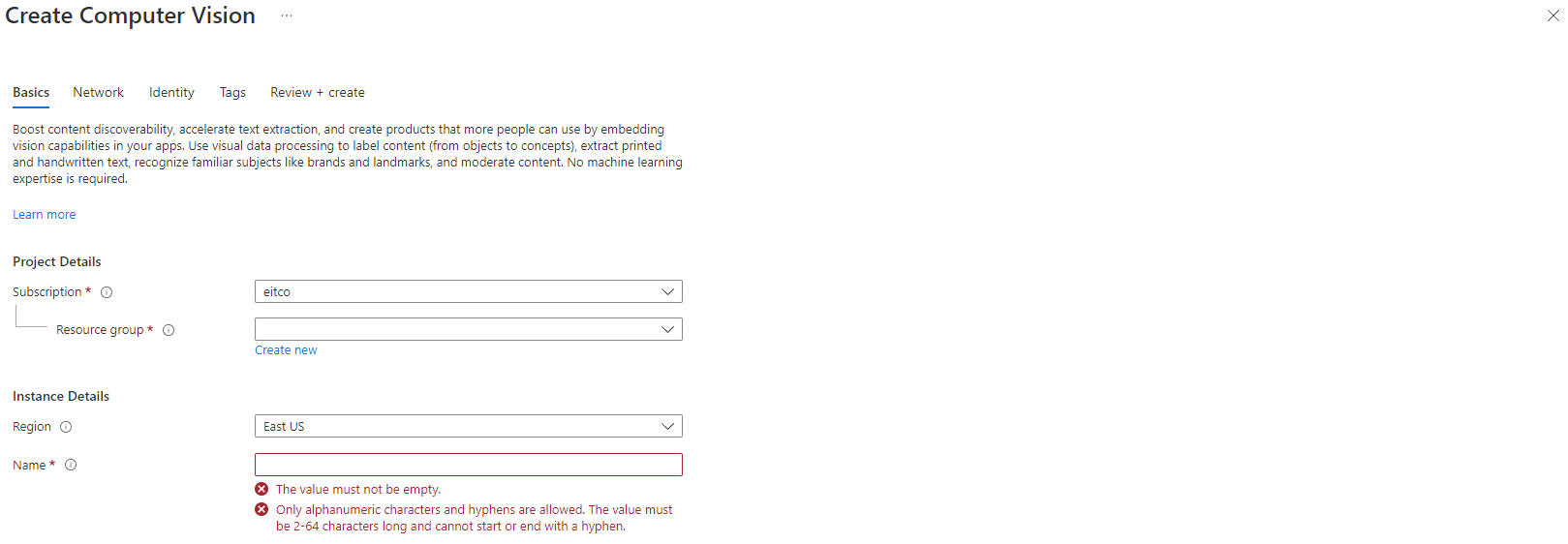
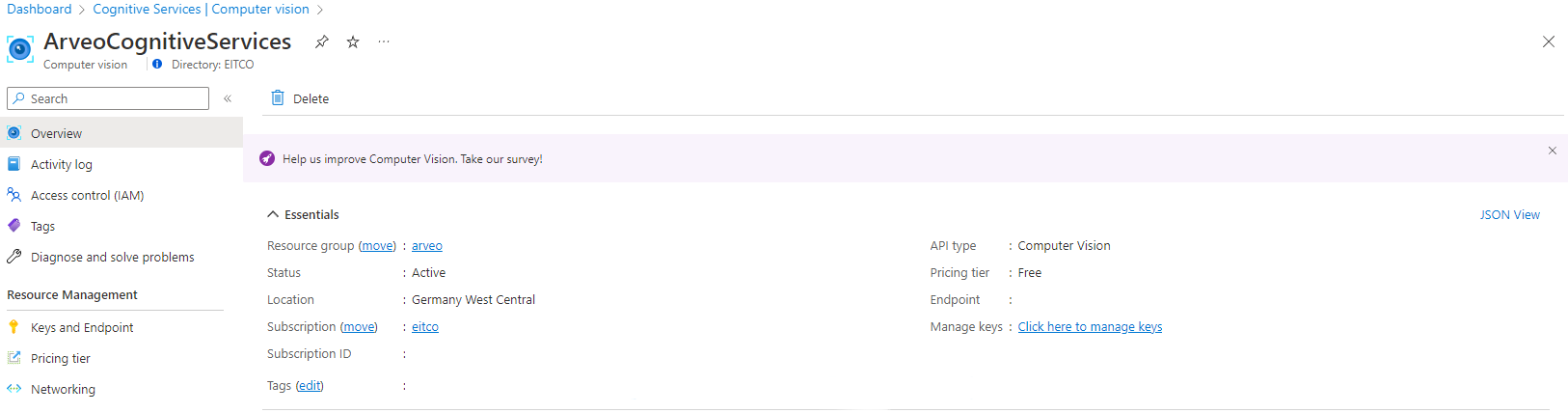
After creating a computer vision service, you need the endpoint. The endpoint can you find in the overview of the service.
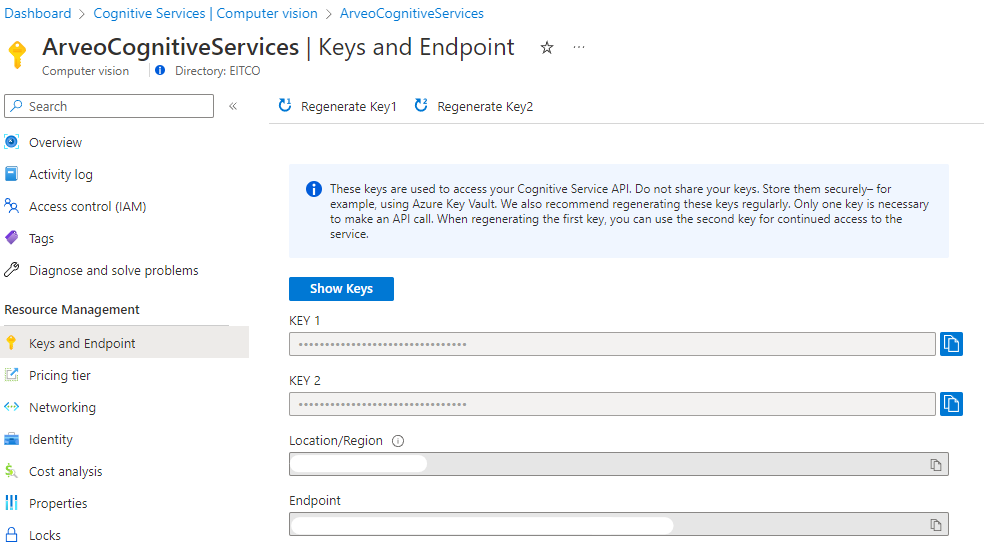
Now you need an access key of your computer vision service.
YAML configuration
In the yaml of the document conversion service you must set the following to use the azure fulltext plugin:
azure:
cognitive:
key: ""
endpoint: ""
ocrDetectionLanguage: "de"
modelVersion: "latest"| The default value for the "ocrDetectionLanguage" value is de (german). The other language you can choose is english. If you want to use english, you can write in your yaml "en". |
Azure computer version models can you find here. === Amazon AWS plugins
The document-conversion-plugins-amazon-aws library provides several
plugins based on amazon aws. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
| If you want to use this plugin you need an Amazon AWS account (also named IAM account). |
A ZIP containing the library and additional dependencies can be downloaded from nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-amazon-aws</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-amazon-aws
de.eitco.commons.conversion.plugins.aws.AwsTextractPdfToSearchablePdfPlugin
Generates a searchable pdf from a scanned pdf with aws textract
| Source media types | Target media types |
|---|---|
|
|
| The AwsTextractPdfToSearchablePdfPlugin has a dependency on the PdfToImagesRenderPlugin (de.eitco.commons.conversion.plugins.oss) |
Setup IAM account and credentials
| If you don’t want to use a technical user for this plugin you can continue with add permission. |
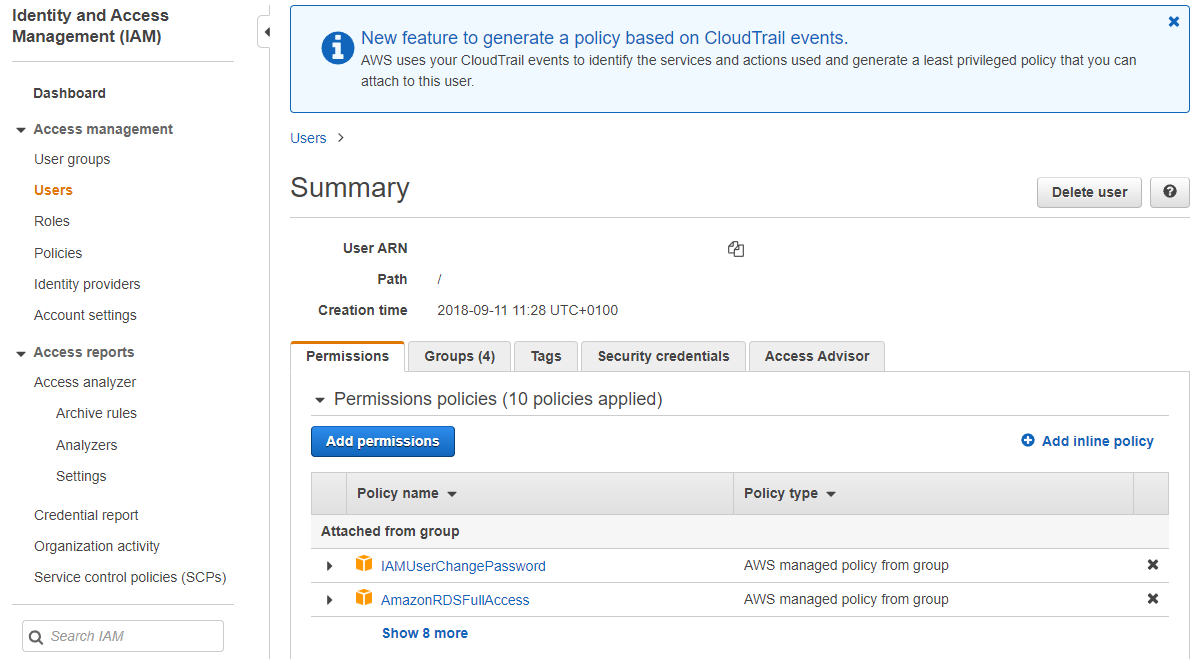
- 1 Create User
-
Login into AWS Console and search for AWS IAM. Here you can create a new user with the Add users button.
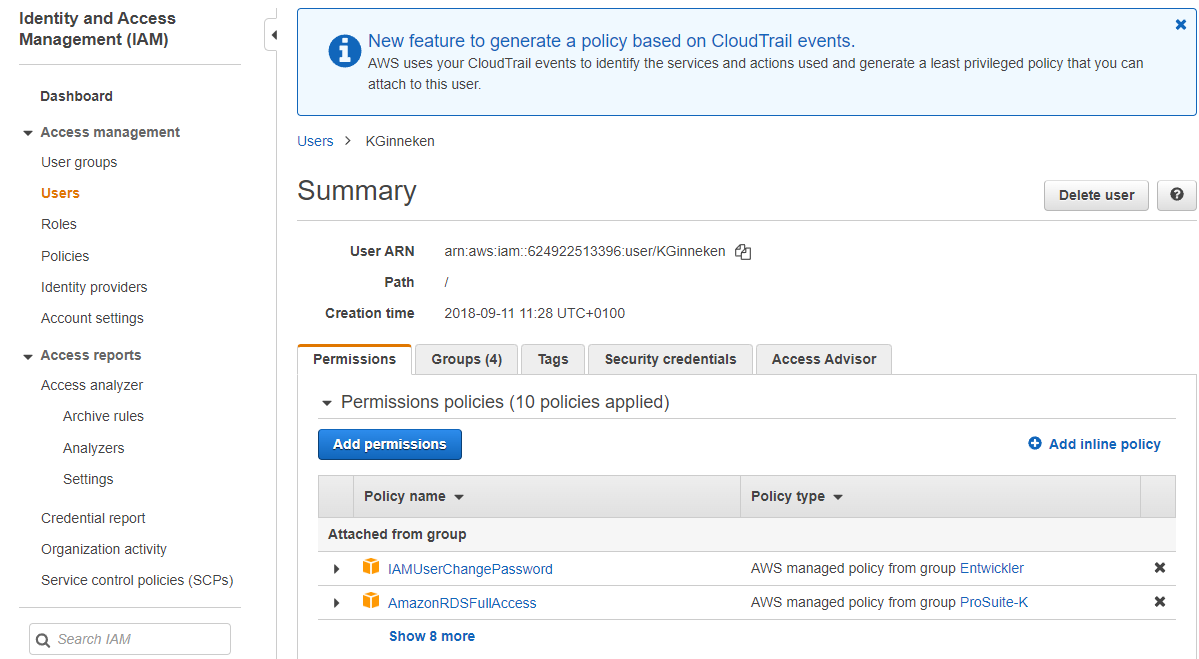
- 2 Add Permission
-
After you create a new user you must add permissions. To do that, go to the newly created user account.
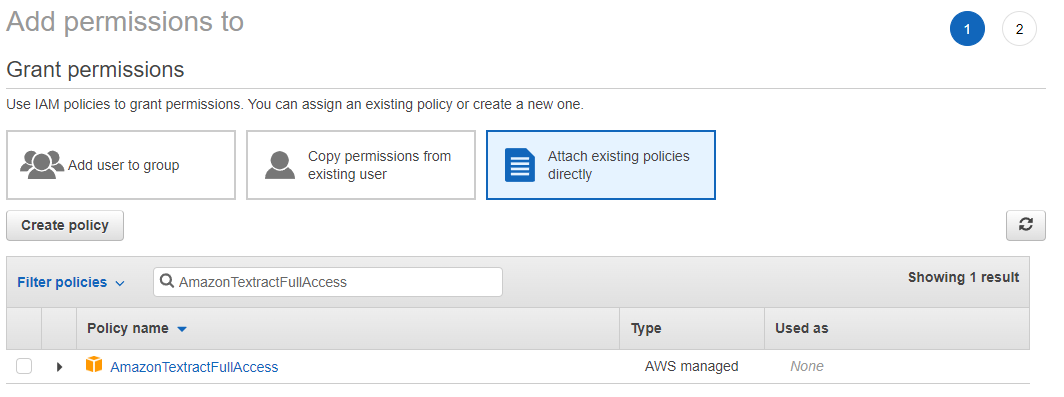
Click on Add permission, then on Attach existing policies and add the AmazonTextractFullAccess permission to the user.
- 3 Create Access Key
-
Now you need to create an access key. Switch to the tab Security credentials.
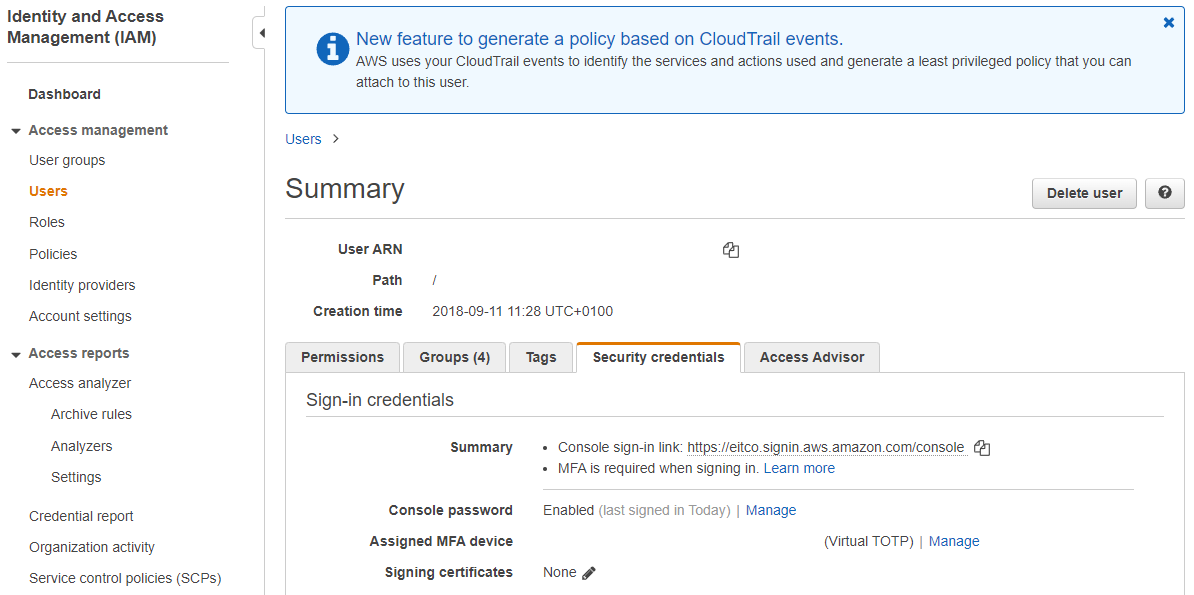
Here you can find acces keys. Create a new access key.
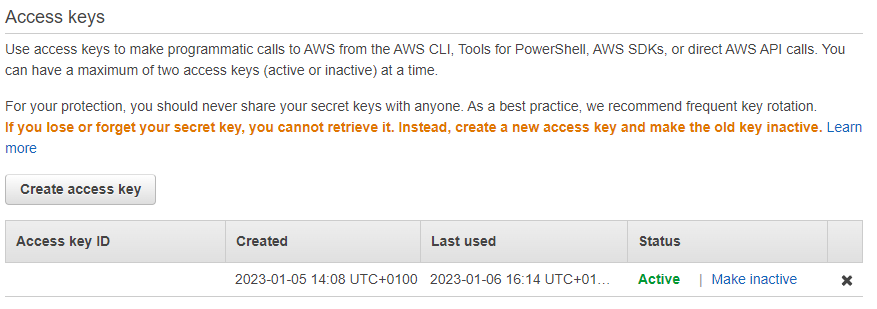
YAML configuration
In the yaml of the Document Conversion Service you must set the following to use the aws textract render plugin:
Here you can find the aws region list.
aws:
accessKey: "XXXXXXXXXXXXXXXXXXXX"
secretKey: "X1XX2XXXXXXXXXXX3XXXXXXXX4XXXXXXX567XXX8"
region: "EU_WEST_1"e-iceblue plugins
| If you want to use the e-iceblue Plugins, you must have an iText license. |
The document-conversion-plugins-e-iceblue library provides several
plugins based on e-iceblue libraries. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
A ZIP containing the library and additional dependencies can be downloaded from Nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-e-iceblue</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-e-iceblue
de.eitco.commons.conversion.plugins.eiceblue.EIcebluePdfToPdfAPlugin
Generates a subtype of pdfa from a pdf with e-iceblue.
| Source media types | Target media types |
|---|---|
|
|
YAML configuration
In the yaml of the document conversion service you must set the following to use the aws textract render plugin:
Here you can find the aws region list.
e-iceblue:
pdfType: "PdfA1A"
license: ""iText Plugins
| If you want to use the iText Plugins, you must have an iText license. |
The document-conversion-plugins-itext library provides several
plugins based on iText libraries. To use the plugins, the jar file of the library must be added to the classpath
of the service. The plugins will be registered automatically.
A ZIP containing the library and additional dependencies can be downloaded from Nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-itext</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>Plugins contained in document-conversion-plugins-itext
de.eitco.commons.conversion.plugins.itext.ITextPdfToSearchablePdfaPlugin
Generates a searchable pdfa out of a scanned pdf with itext.
| Source media types | Target media types |
|---|---|
|
|
| The ITextPdfToSearchablePdfaPlugin has a dependency to the PdfToImagesRenderPlugin (de.eitco.commons.conversion.plugins.oss) |
Installing Tesseract
If you want to use the ITextPdfToSearchablePdfaPlugin you need to install tesseract on you operating system.
-
Download and install tesseract from this page https://github.com/tesseract-ocr/tessdoc/blob/main/Downloads.md.
-
For Ubuntu for example: sudo apt install tesseract-ocr
-
-
Add tesseract to the path enviroment variables. For example in Windows you must add the following lines in the path:
-
{path to tesseract}\Tesseract-OCR\tessdata
-
YAML configuration
In the yaml of the document conversion service you must set the following:
itext:
pathToTessData: "{path to tesseract}/Tesseract-OCR/tessdata"
pdfLang: "deu"
iTextLicensePath: "{path to itext license}/itextkey.json"For the pdfLang option you can look at the following page tesseract model list
XRechnung plugin
The document-conversion-plugins-x-rechnung library provides a plugin that can create PDF and HTML renditions of
XRechnung XML data. It is using the x-rechnung-toolkit-service to create the actual renditions.
A ZIP containing the library and additional dependencies can be downloaded from nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-x-rechnung</artifactId>
<type>zip</type>
<classifier>zip</classifier>
<version>10.2.0-SNAPSHOT</version>
</dependency>| Source media types | Target media types |
|---|---|
|
|
Document Converter Plugin
The ToPdfDocumentConverterPlugin provides a way to render various document formats to PDF using the EITCO DocumentConverter service.
This service wraps the SyncFusion library and must be deployed as a separate Docker container.
The plugin does not require any additional dependencies. It can be downloaded from the nexus using the following maven coordinates:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-plugins-documentconverter</artifactId>
<version>10.2.0-SNAPSHOT</version>
</dependency>Configuration
The plugin can be configured using the following properties in your application.yaml:
documentconverter:
base-url: "http://127.0.0.1:8080" # The base URL of the DocumentConverter service| Property | Description | Default |
|---|---|---|
|
The base URL where the DocumentConverter service is reachable. |
Plugins contained in document-conversion-plugins-documentconverter
de.eitco.commons.conversion.plugins.documentconverter.ToPdfDocumentConverterPlugin
Renders Microsoft Office Documents and some other formats to PDF using the EITCO DocumentConverter service, which wraps the SyncFusion library.
| Source media types | Target media types |
|---|---|
|
|
de.eitco.commons.conversion.plugins.documentconverter.ToImageDocumentConverterPlugn
Renders Microsoft Office Documents and some other formats to JPEG using the EITCO DocumentConverter service, which wraps the SyncFusion library.
| Source media types | Target media types |
|---|---|
|
|
Usage
The following examples show how to perform different conversions using the client API of the conversion service. The following dependency is required to get access to the http client API:
<dependency>
<groupId>de.eitco.commons</groupId>
<artifactId>document-conversion-http-client-spring-boot-starter</artifactId>
<version>${project.version}</version>
</dependency>The client API instances can be obtained using injectable factory classes.
@Autowired
private FulltextResourceClientFactory fulltextClientFactory;
@Autowired
private DocumentConversionResourceClientFactory conversionClientFactory;
The utility class de.eitco.commons.io.ContentAnalyzer contained in cmn-commons-io can be used to determine the mime
type of a file.
|
Converting an image to PDF
This example shows how to convert an image of type JPEG to PDF.
DocumentConversionResourceClient client = conversionClientFactory.newClient(); (1)
File jpeg = new File("src/test/data/source/source_inputstreamlist_images/jpgSample.jpg");
try (FileInputStream inputStream = new FileInputStream(jpeg)) {
InputStream rendition = client.render(MediaType.IMAGE_JPEG_VALUE, MediaType.APPLICATION_PDF_VALUE, inputStream); (2)
try (FileOutputStream out = new FileOutputStream("target/rendition.pdf")) {
IOUtils.copy(rendition, out); (3)
}
}| 1 | Creates a new client instance using the DocumentConversionResourceClientFactory |
| 2 | Sends a request for the rendition to the service. The source- and target-mimetypes are strings and can be obtained from any utility class containing standard mime type strings. |
| 3 | Saves the rendition to a file using Apache Commons IO IOUtils |
Extracting text from a PDF file
This example shows how the API can be used to extract text content from a PDF file.
FulltextResourceClient client = fulltextClientFactory.newClient(); (1)
File pdf = new File("src/test/fulltext-data/source/test.pdf");
try (FileInputStream inputStream = new FileInputStream(pdf)) {
String text = client.extractText(MediaType.APPLICATION_PDF_VALUE, inputStream); (2)
}| 1 | Creates a new client instance using the FulltextResourceClientFactory |
| 2 | Sends a request for the extraction to the service. The source-mimetype is a string and can be obtained from any utility class containing standard mime type strings. |
Combining multiple images to one PDF
This exmaple shows how to combine multiple images to a single PDF file.
DocumentConversionResourceClient client = conversionClientFactory.newClient(); (1)
File image1 = new File("src/test/data/source/source_inputstreamlist_images/jpgSample.jpg");
File image2 = new File("src/test/data/source/source_inputstreamlist_images/pngSample2.png");
List<ConversionMultipartBodyElement> inputStreamAndMediaTypeList = new ArrayList<>();
FileInputStream fileInputStream1 = null;
FileInputStream fileInputStream2 = null;
try {
fileInputStream1 = new FileInputStream(image1);
fileInputStream2 = new FileInputStream(image2);
inputStreamAndMediaTypeList.add(new ConversionMultipartBodyElement(MediaType.IMAGE_JPEG_VALUE, fileInputStream1)); (2)
inputStreamAndMediaTypeList.add(new ConversionMultipartBodyElement(MediaType.IMAGE_PNG_VALUE, fileInputStream2));
InputStream combinedPdf = client.combineToPdf(inputStreamAndMediaTypeList); (3)
} finally {
fileInputStream1.close();
fileInputStream2.close();
}| 1 | Creates a new client instance using the DocumentConversionResourceClientFactory |
| 2 | Create the body elements for the multipart request that will be sent to the service |
| 3 | Sends the request to the service |
Monitoring
Metrics
The Document Conversion Service provides metrics that can be used to monitor the performance. The following metrics are available:
-
dcs.render.time: Records the time it took to perform one rendering request as well as a counter for the number of performed requests. -
dcs.render.errors: A counter for errors that occurred while rendering. -
dcs.extract.time: Records the time it took to perform one fulltext extraction request as well as a counter for the number of performed requests. -
dcs.extract.errors: A counter for errors that occurred while performing fulltext extractions.
Each of these metrics contains tags for the source and (if applicable) the target mime type in standard string representation (for example: image/jpeg) and for the size of the original content. The size metric uses size ranges: 0-1MB, 1-10MB, 10-100MB, 100-1000MB and >1000MB.
The recording of those metrics can be disabled by setting the parameters management.metrics.enable.dcs.render or
management.metrics.enable.dcs.extract to false.
Open Telemetry
The Document Conversion Service supports the usage of Open Telemetry. Spans are created for the methods of each render plugin. The outermost span will contain the ID and the tenant (if available) of the user who performed the request.